
CUDA vs. C++ vs. Node.js: Genomic Algorithm Performance
A few weeks ago I devised a new genomic search algorithm to search for some specific patterns inside the human genome.
In order to get my algorithm running in reasonable time windows (hours instead of years), I ended up implementing the algorithm in JavaScript (Node.js), C++, and CUDA. Not sure how many times all of these languages/runtimes have been compared head-to-head, so I thought the perf results might be blog-worthy. Especially considering the performance difference was greater than 1000x!
The algorithm itself is a variation of the longest common substring problem, but due to the nature of the variation it can’t be solved using suffix trees. The next most efficient option (in big O terms) requires dynamic programming.
The two search strings are 400,000 characters and 6,000,000,000 characters long. All data is loaded into memory before the algorithm begins, so IO does not affect the performance results.
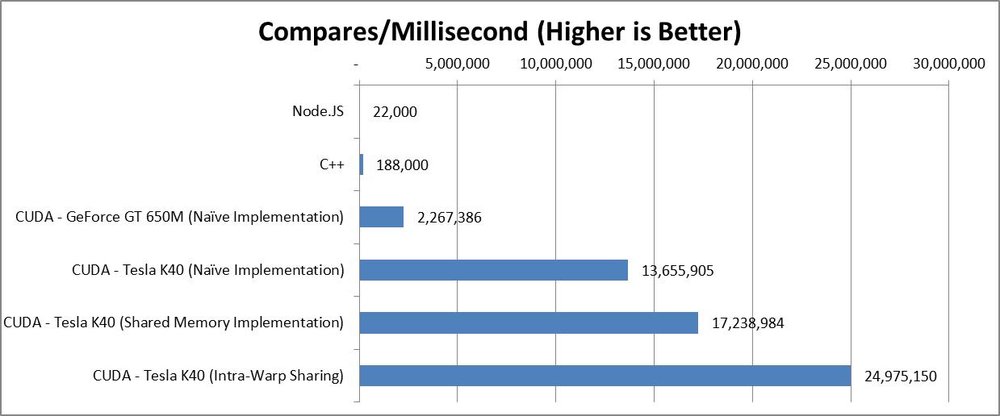
Results:
Language 1: Node.JS/JavaScript
Friends and colleagues have been encouraging me for years to embrace JavaScript. Having heard wonderful things about IO performance in Node.JS, I figured this was a good excuse to learn the language and framework. Implementation was super-easy, as was generating readable HTML output.
Unfortunately, performance was abysmal. Node.JS is single threaded. On my datasets, the algorithm would have taken months to complete.
Language 2: C++
Naïve C++ implementation. No multithreading or SIMD, just STL and reasonable memory allocation. ~10x perf improvement over Node.JS/Javascript.
Language 3: CUDA
Naïve Implementation
My initial implementation ran on my laptop’s NVidia GeForce GT 650M chip with the latest CUDA drivers.
Both search strings were loaded into device memory. Each thread would perform one comparison, and each invocation would fill one row in the LCSuff table and dump the result to device memory. Only two rows are ever used at one time, so only enough memory for two rows need be allocated.
>10x perf improvement over C++ running on my Intel Core i7 @ 2.70 GHz
Tesla K40
Thanks to the generous folks at NVidia and Microway, I was given remote access to a server running an NVIDIA Tesla K40.
Out of the gate, the algorithm performed 5x faster.
Shared Memory and Intra-Warp Sharing
I now had the performance I needed. At 500x faster than Node.JS, the algorithm completed within hours. I had another day on the K40, so I figured I’d see what performance I could squeeze out of some basic optimizations.
Up until now, my algorithm was performing one character comparison per thread and then outputting the results to device memory (there was a bit more math going on, but it was fundamentally memory-bound).
The primary optimization was to take a hierarchical approach. Do multiple compares per thread, and store the intermediate results in thread Shared Memory, performing 256/512/1024 compares per thread, dumping the output in shared memory after each one, and then dumping the result to device memory after all threads have completed. Doing so requires you to ‘throw out’ a number of comparisons that will be invalid because the data they need won’t have been computed by your local thread pool. Still a net win, however, because you save a great deal of latency. Another 30% performance improvement.
The next level of optimization involved adding another level to the hierarchy. The K40 runs threads in 16-wide “warps”. By using intra-warp communication, the intermediate results computed by neighbor threads could be accessed, allowing each thread to compute up to 16 results before even having to output to shared memory. Spill to shared memory after 16 iterations, then to device memory after 16 of those. Another 50% performance improvement.
These optimizations would only run on the K40, as they significantly increased the time spent in the GPU per invocation, which caused a WDDM timeout on my laptop GPU. On the remote server, the K40 wasn’t used for desktop rendering so it was more forgiving.
I’d like to thank the folks at Nvidia and Microway for providing free access to the K40 for this GPGPU adventure.
K40 System Specs:
(2) 4-core Xeon E5-2643 v2 CPUs @ 3.5GHz
(1) NVIDIA Tesla K40, (1) NVIDIA Quadro K6000, and (1) NVIDIA Quadro K600
64GB DDR3 1866MHz Memory
240GB SSD
It’s not quite a fair competition I think.
CUDA is in parallel, so why not put C++ / JS in parallel and have a try.
Also, seems you just started JS while having use C for long time. I believe the performance of JS could be improved a lot if you know more about it, avoid common mistakes that will hurt performance when coding JS, such as lots of global var access or copy whole object instead of address.